

Umetna inteligenca – čarovnik ali statistični stroj?
Piše: Sebastian Pleško
Zadnje čase se veliko govori o umetni inteligenci, predvsem pa se s tem imenom pogosto poistoveti ChatGPT oziroma LLM (large language models – veliki jezikovni modeli). Marsikdo meni, da bo to orodje prevzelo svet in ukinilo mnogo delovnih mest. Morda bo katero od teh res izginilo, kot se je že zgodilo z uvedbo elektronskega računala, ko so bila odpravljena delovna mesta človeških kalkulatorjev, vendar je verjetneje, da se bodo delovna mesta le spremenila in da bo umetna inteligenca ostala predvsem uporabno orodje.
Preden razmišljamo o vplivu umetne inteligence in o tem, kako bo (ali ne bo) spremenila življenje, kot ga poznamo, moramo najprej stopiti korak nazaj ter razumeti njen način delovanja in omejitve. Namen tega članka je predvsem pokazati, da LLM-ji v osnovi niso čarovnija, temveč zgolj statistični stroji, ki izkoriščajo že obstoječe znanje.
Vzemimo preprost primer: kako bi umetna inteligenca prepoznavala številke. Algoritem bi lahko številko razdelil na mrežo 3 × 3 in za vsak kvadratek izračunal, kolikšen delež je črn. Popolnoma bel kvadrat bi dobil vrednost 0, popolnoma črn pa 1 (glej sliko 1).
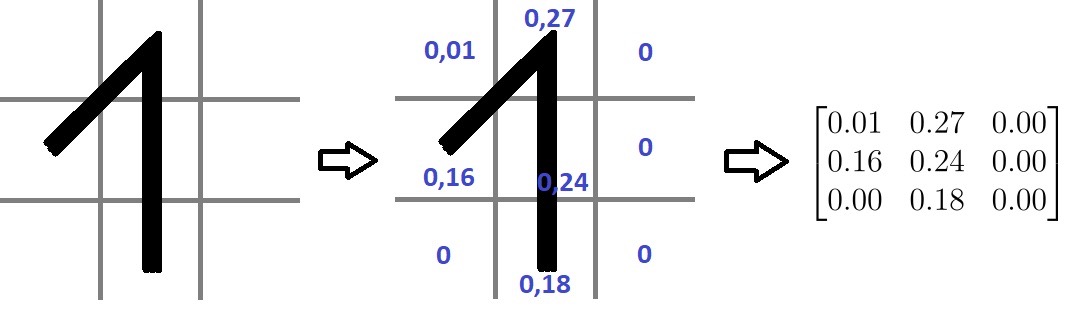
Slika 1: številka 1, razdeljena na 9 delov s pomočjo mreže 3 × 3. Vsakemu kvadratku določimo razmerje med belino (0) in črnino (1), nato pa to zapišemo v obliki matrike.
Če bi tako obdelali vse števke od 0 do 9, bi za vsako dobili svojo matriko. Neznano število bi lahko prepoznali tako, da bi iz njega sestavili matriko in jo primerjali s poznanimi.
A tak sistem hitro pokaže omejitve: deloval bi le pri isti pisavi, pri enaki velikosti in poravnavi. Že zamik, zasuk ali drugačna debelina črte bi povzročili zmedo.
Seveda je ta primer daleč najosnovnejši in tako obstaja mnogo načinov, kako izboljšati razpoznavanje. V preteklosti so se uveljavile različne metode strojnega učenja, danes pa med najsodobnejše spada arhitektura transformer, ki omogoča, da vsak kvadratek lahko »pogleda« vse druge in se iz podatkov sam nauči, kateri odnosi so pomembni. Pri številki 1 bi na primer iz množice primerov prepoznala, da se navpična povezava kvadratkov pojavlja zelo pogosto, in bi tej povezavi pripisala večji pomen. Tako bi sama prepoznala vzorec, ne da bi ji morali vnaprej napisati pravila.
Pri besedilu seveda ne gre za kvadratke, ampak za to, da ga razbijemo na posamezne besede (tokene). Vsak token se pretvori v številčni vektor (embedding), podobno kot smo prej številko 1 zapisali v obliki matrike. Množica teh vektorjev nato tvori t. i. matriko embeddingov. Ti vektorji živijo v prostoru z mnogo dimenzijami, kjer računalnik meri podobnost glede na bližino v tem večdimenzionalnem prostoru. Ko tako množico pomnožimo z naučenim »besednim zakladom« modela – veliko matriko uteži, ki opisuje povezave med besedami – dobimo rezultat, iz katerega lahko model napove naslednjo najbolj verjetno besedo.
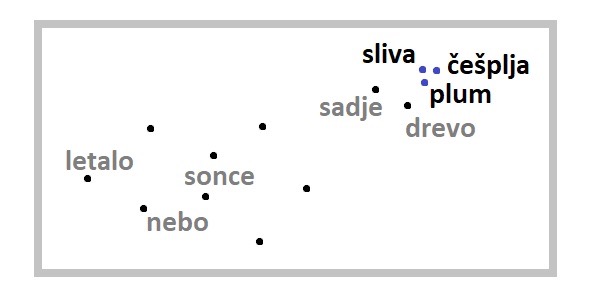
Slika 2: izmišljen primer podobnosti – bližine besed v 2D prostoru.
Tak način »razumevanja« sveta preko vektorjev je zanimiv tudi zato, ker so si vektorji za sinonime ali prevode zelo blizu. Tako se jezikovni modeli razmeroma enostavno učijo več jezikov: če jim damo dovolj besedil, sami prepoznajo, da imajo besede podoben pomen. Tako so si vektorji za sliva, češplja in plum (angl. za slivo) bližje v tem večdimenzionalnem prostoru.
Model pa ne izbira vedno samo najbolj verjetnih naslednjih besed, sicer bi bili odgovori dolgočasni in vedno enaki. Zato imajo modeli parameter temperatura, ki spremeni verjetnostno porazdelitev možnih odgovorov: pri višji temperaturi je več raznolikosti (včasih izberejo drugo ali tretjo najbolj verjetno možnost), pri nižji pa so odgovori bolj predvidljivi. S tem sicer postanejo bolj ustvarjalni, a se hkrati poveča tveganje, da povedo kaj napačnega. Ključna posledica: model ne ve, ali je odgovor resničen, ker nima povezave z resničnostjo, ampak samo s statistiko jezika, torej izbira le statistično verjetno možnost. Zato lahko samozavestno poda napačen odgovor: temu rečemo halucinacija.
Iz tega je tudi jasno, da modeli niso dobri pri ustvarjanju povsem novega znanja: s kompleksnejšimi matematičnimi nalogami se pogosto mučijo, razen če lahko uporabijo zunanja orodja. Odlični so pri dejstvih, povzetkih in povezovanju že znanih stvari, manj uspešni pa pri izvirnih odkritjih. Lahko bi rekli, da gre za nekakšno obliko »zdrave kmečke pameti«. To ne pomeni, da ne morejo sestavljati novih, zanimivih kombinacij, pomeni le, da novost izhaja iz preureditve ali sinteze znanega.
Učenje takih modelov zahteva veliko računske moči in velike količine zmogljivih grafičnih kartic (GPU), ki so učinkovite pri množičnih vzporednih vektorskih računih. Postopek je dolg,
zato imajo osnovni modeli običajno zamik glede najnovejših informacij. Sama uporaba že naučenih, manjših modelov je bistveno manj zahtevna in deluje tudi na zmogljivejših običajnih grafičnih karticah, bolj zmogljivi modeli pa zahtevajo zmogljivo in drago strojno opremo. Vsak pa lahko lokalno preizkusi kak enostavnejši LLM: prenese orodje Ollama (ollama.com) in ga zažene na svojem računalniku.
Zaradi omenjenih omejitev se vse pogosteje uporablja pristop, v katerem so LLM le »možgani« sistema, ta pa je povezan z zunanjimi orodji. Na primer: lahko napiše programsko kodo v Pythonu, jo izvede in uporabi rezultat, to je pri matematiki praviloma zanesljiveje. Podobno lahko za najnovejše informacije prikliče spletni iskalnik in vključi aktualno znanje ali pa se poveže z bazo dokumentov (z vektorskimi predstavitvami posameznih strani) in iz nje črpa lokalne informacije: denimo poišče točno določeno e-pošto, račun ali pogodbo.
Novejši pristopi vključujejo tudi t. i. chain of thought oziroma verigo sklepanja: model poskuša zapleteno vprašanje razbiti na manjše korake in jih reševati zaporedno. Tako se bolje sooči s kompleksnimi nalogami, za katere nima neposrednega znanja, a ga lahko sestavi iz kombinacije različnih informacij. Seveda pa veriga sklepanja sama po sebi ne zagotavlja resničnosti. Če so vmesni koraki napačni, je napačen tudi zaključek, saj gre za način, kako model strukturira besedilo, ne za dejansko logično sklepanje.
Najbolj zaskrbljujoče je morda to, da se LLM-je pogosto uporablja za preverjanje resničnosti, pri čemer se ne upošteva, da imajo ti modeli poleg tehničnih omejitev tudi notranjo pristranskost, ki izhaja iz podatkov, ki so jim bili dani, in iz vgrajenih pravil. Npr. kitajski modeli pogosto ne odgovarjajo na občutljive teme iz kitajske zgodovine, prve verzije Googlovega Gemini so imele težave s pristranskim prikazovanjem podob, različice ChatGPT pa so kazale vedenja, ki so se preveč prilagajala sogovorniku in s tem povzročala zmedo.
Skratka, vsak LLM ima svoj pogled na svet, svojo »resnico«. Njegovi odgovori so vedno oblikovani skozi filter podatkov in pravil, po katerih je bil naučen, pri čemer ni izključeno, da imajo različni akterji (države, podjetja) tudi svoje interese pri tem, kakšne modele ponujajo javnosti, pod kakšnimi pogoji in s kakšno »resnico«.
Nevarnost LLM-jev zato ni v pisanju besedil, temveč v tem, da postanejo naš filter resničnosti. Če jim prepustimo presojo, katera novica je vredna zaupanja, kateri kandidat ustreza razpisu za delovno mesto ali celo, kdo je imel prav v osebnem konfliktu, bomo nehote prevzeli notranje pristranskosti modela, ki jih sicer ne poznamo. Pri povzetkih novic je to še posebej zahrbtno: kitajski model bo prizanesljivejši do kitajskih interesov, korporativni model pa do korporacijskih. Ko enkrat začnemo svet gledati skozi tak filter, izgubimo lastno presojo in ostane nam le iluzija nevtralnosti.
LLM-ji so lahko uporabno orodje, a le, če se zavedamo, da niso nevtralni, vsevedni in niti nujno točni. Zaradi svojih omejitev, pristranskosti in političnih kontekstov jih je smiselno uporabljati premišljeno: kot dopolnilo, ne kot resnico. Brez kritične presoje se lahko iz pomoči hitro spremenijo v tveganje.
Naslovna slika: Joseph-Wright of Derby, Alkimist odkriva fosfor, 1771. Sliko hrani Muzej in umetnostna galerija v Derbyju











